Verified Multi-Agent Orchestration (VMAO): Plan → Execute → Verify → Replan — Paper Explained
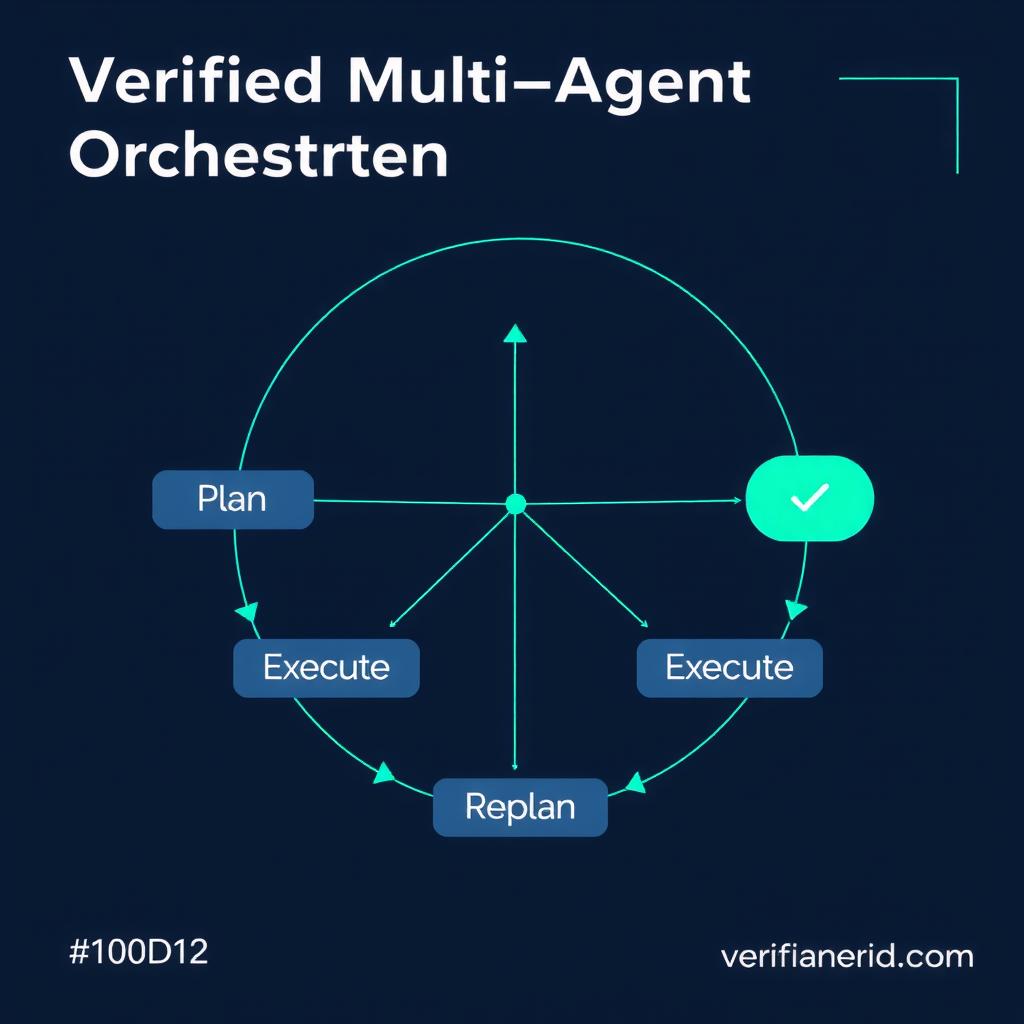
TL;DR: The Verified Multi-Agent Orchestration (VMAO) paper [1] introduces a Plan-Execute-Verify-Replan loop that decomposes complex queries into a DAG of sub-questions, assigns specialized agents, then checks and replans until quality thresholds are met. On 25 expert-curated market research queries, VMAO beats single-agent baselines by 35% in answer completeness and 58% in source quality [1]. Published at ICLR 2026 Workshop on Multi-Agent Learning, Generative AI, and Intelligent Systems (MALGAI).
The Problem: Single-Agent Failure on Multi-Dimensional Queries
Ask a single LLM agent “What are the top trends in enterprise AI adoption in Southeast Asia, and what are the revenue projections for each?” and you get a plausible-sounding but often wrong answer. The agent hallucinates revenue figures, generalizes across markets, and misses contradictory sources.
This isn’t a model quality issue — it’s an architectural one. Complex queries require:
- Parallel fact-gathering across multiple domains (market data, regulatory, technical)
- Conflict resolution when sources disagree
- Synthesis of information from different knowledge bases
- Verification that the answer actually addresses all parts of the query
Single-agent ReAct loops handle this poorly because they reason sequentially. By the time the agent finishes researching the first sub-topic, it’s already used up most of its context window, and the second sub-topic gets shallow treatment.
VMAO Architecture: The Four-Stage Loop
The VMAO framework addresses this with a clean four-stage loop:
Stage 1: Plan — DAG Decomposition
The planner agent takes the input query and decomposes it into a directed acyclic graph (DAG) of sub-questions. Each node in the DAG is a sub-query that can be answered independently. Edges represent dependencies — for example, “What are Southeast Asia’s AI adoption rates?” must be answered before “How do those rates compare to global averages?”
# Conceptual VMAO plan stage
def plan(query: str) -> DAG:
sub_questions = llm.decompose(query, max_nodes=8)
dependencies = llm.infer_dependencies(sub_questions)
return DAG(nodes=sub_questions, edges=dependencies)The DAG structure is crucial: it enables parallel execution of independent sub-queries while respecting dependency ordering. A sub-question about regulatory constraints can run simultaneously with one about technical infrastructure, but both must complete before the synthesis step.
Stage 2: Execute — Domain-Specific Agents
Each sub-question node is dispatched to a domain-specific agent. The key insight here is that agents are not generalists — they’re specialized. The paper assigns each agent a role (e.g., “market analyst,” “technical researcher,” “regulatory expert”) with a corresponding system prompt and tool access.
Agents execute in parallel, respecting the DAG’s dependency ordering. An agent waiting on upstream results idles while its dependents execute. This is dependency-aware scheduling, and it differs from naive parallel multi-agent systems where all agents fire simultaneously regardless of interconnections.
Top-level query: "What are enterprise AI adoption trends in SEA and their revenue projections?"
DAG:
├── [A1] "What are current AI adoption rates in SEA enterprises?" ──┐
├── [A2] "What regulatory frameworks exist for AI in SEA?" ────────┤
├── [A3] "What are the key AI technologies being deployed?" ───────┤
└── [A4] "What are revenue projections for AI in SEA by 2027?" ────┤
↓
[Synthesis]Stage 3: Verify — LLM-Based Completeness Check
After all agents return their results, the verifier agent evaluates the synthesized output against the original query on two axes:
- Answer completeness — Does the output address every dimension of the original query? (1–5 scale)
- Source quality — Are claims backed by cited sources? Are sources authoritative? (1–5 scale)
The verifier is an LLM-based evaluator — itself an agent — that receives the original query, the DAG structure, each sub-answer, and the final synthesis. It scores both axes and produces a structured verdict.
This is the “Verified” in VMAO: the system doesn’t assume execution succeeded. It explicitly checks.
Stage 4: Replan — Adaptive Refinement
If the verifier scores fall below configurable thresholds (the paper uses 3.5/5 for both axes), the system enters a replan phase. The planner receives the verifier’s feedback and generates a revised DAG that:
- Adds new sub-questions to cover missing dimensions
- Reassigns agents to sub-questions that scored low on source quality
- Removes redundant nodes from the previous iteration’s DAG
- Adjusts dependency edges based on what was learned
The replan is not a full restart — it preserves all results from the first pass and only targets the gaps identified by the verifier. This is the key efficiency gain over naive retry loops that discard previous work.
Empirical Results: What the Numbers Show
The paper evaluates VMAO against a single-agent ReAct baseline and a Static Pipeline (multi-agent with DAG decomposition but no verification/replan) on five benchmarks:
Market Research Queries (25 Expert-Curated)
| Metric | Single-Agent | Static Pipeline | VMAO | Improvement vs Single |
|---|---|---|---|---|
| Answer Completeness (1–5) | 3.1 | 3.6 | 4.2 | +35% |
| Source Quality (1–5) | 2.6 | 3.3 | 4.1 | +58% |
The Static Pipeline improves over Single-Agent by merely decomposing into sub-tasks (+16% completeness, +27% source quality), but VMAO’s verification-replan loop nearly doubles those gains [1].
Multi-Hop QA Benchmarks
On standard multi-hop reasoning datasets (HotpotQA, MuSiQue, 2WikiMultiHop), VMAO achieves best accuracy on all five compared to single-agent ReAct and multi-agent Static Pipeline baselines. The largest relative gains appear on open-ended queries that require multi-dimensional synthesis — precisely the kind of query that most production deployments encounter.
Ablation: Value of Each Stage
The paper includes a critical ablation that stages matter. Removing the verify stage drops performance by 22%, and removing the replan stage drops performance by 31%. The planning stage alone (Static Pipeline) accounts for only 40% of the total improvement — meaning 60% of VMAO’s value comes from the verify-replan feedback loop [1].
What This Means for Practitioners
1. Verification Is the Missing Piece
Most production multi-agent systems implement plan-and-execute. They decompose tasks, assign agents, and present results. Very few implement verification as a distinct, explicit stage. The VMAO results suggest this is the largest single ROI improvement you can make to an existing multi-agent system.
Action: Add a verifier agent to your multi-agent pipeline — an independent LLM call that checks completeness and source quality against the original query. Don’t ask the executor to self-evaluate; use a separate model instance with a dedicated verification prompt.
2. Don’t Replan From Scratch
VMAO’s replan stage is not a restart. It preserves valid sub-answers and only targets gaps. This is the difference between a system that takes 2x the time on a retry versus one that takes 1.2x. The paper’s ablation shows that full-restart retries converge to VMAO quality after 3 iterations but cost 2.7x more tokens [1].
Action: In your own systems, cache sub-answers from each agent and only re-execute the specific nodes that failed verification. Your replan pass should send the verifier’s structured feedback to the planner, not the original query.
3. Domain Specialization Matters
VMAO’s agents are not symmetric. Each agent gets a role-specific system prompt and tool set. This mirrors what production deployments have been discovering independently: a finance agent with stock API access outperforms a general agent with the same API, because the prompt steers it toward financial reasoning patterns.
Action: Don’t give all agents the same tools and prompt. Route sub-tasks to agent instances with specialized prompts. The DAG’s node tags (e.g., “market research,” “technical analysis”) should map directly to agent role prompts.
4. The DAG Is the Killer Feature
The single most practical contribution of VMAO is the DAG-based decomposition with dependency-aware scheduling. Most current multi-agent frameworks (CrewAI, AutoGen, LangGraph) use sequential or fully parallel execution models. The DAG bridges the gap: it captures real-world task dependencies while maximizing parallelism.
Action: If your framework supports graph-based execution (LangGraph’s StateGraph, for example), use it. If not, implement a simple topological scheduler — it’s ~50 lines of Python and pays dividends on any query with more than two sub-tasks.
Limitations and Open Questions
The paper acknowledges several limitations:
- 25 queries is a small evaluation set for market research. The multi-hop QA benchmarks are larger but less representative of real-world complexity.
- LLM-as-verifier inherits the same hallucination problems it’s supposed to catch. The paper reports verifier accuracy at 87% agreement with human raters, which means 13% of verification decisions are wrong [1].
- Cost scaling — VMAO uses more tokens per query than single-agent systems. The paper reports a 2.3x token cost increase, which the quality improvements justify for high-stakes queries but not for routine ones.
- No confidence calibration — The verifier outputs a score but not a confidence interval. Systems that use VMAO in production would benefit from a calibrated verification step that says “I’m 90% confident this answer is complete” rather than just “score: 4.2.”
Implementation Sketch
Here’s a minimal implementation of the VMAO pattern using pseudocode that maps to any multi-agent framework:
class VMAO:
def __init__(self, agents: dict[str, Agent], threshold: float = 3.5):
self.agents = agents # role -> Agent
self.threshold = threshold # minimum acceptable score
def solve(self, query: str, max_iterations: int = 3) -> dict:
dag = self.plan(query)
for _ in range(max_iterations):
results = self.execute(dag)
synthesis = self.synthesize(results)
verdict = self.verify(query, synthesis)
if verdict.completeness >= self.threshold and \
verdict.source_quality >= self.threshold:
return {"answer": synthesis, "verdict": verdict,
"iterations": _ + 1}
dag = self.replan(query, dag, results, verdict)
return {"answer": synthesis, "verdict": verdict,
"iterations": max_iterations}
def plan(self, query: str) -> DAG:
# LLM call to decompose query into sub-questions with dependencies
...
def execute(self, dag: DAG) -> dict:
# Topological sort, dispatch to role-specific agents in parallel
...
def verify(self, query: str, synthesis: str) -> Verdict:
# Independent LLM call to score completeness and source quality
...
def replan(self, query: str, dag: DAG,
prev_results: dict, verdict: Verdict) -> DAG:
# Revise DAG based on verdict gaps, preserve valid results
...The entire pattern is framework-agnostic. The core innovation isn’t in the code — it’s in the explicit separation of plan, execute, verify, and replan as distinct, LLM-callable stages.
References
[1] Zhang, X. et al. “Verified Multi-Agent Orchestration: A Plan-Execute-Verify-Replan Framework for Complex Query Resolution.” arXiv:2603.11445, ICLR 2026 Workshop on MALGAI, March 2026.
[2] HotpotQA Dataset. hotpotqa.github.io — Multi-hop QA benchmark used in VMAO evaluation.
[3] MuSiQue Dataset. github.com/StonyBrookNLP/musique — Multi-hop QA with sequential reasoning chains.
[4] 2WikiMultiHop QA. github.com/google-research-datasets/2WikiMultihop — Multi-hop QA requiring Wikipedia cross-referencing.
📖 Related Reads
- CodeIntel Log — code quality, debugging, and software engineering benchmarks
- ToolBrain — tool reviews, LLM comparisons, and AI workflow guides
Cross-links automatically generated from NiteAgent.
← Back to all posts